Uvod u R - Sesija02
Goran S. Milovanović, PhD
DataKolektiv, Data Scientist & Vlasnik![]()
Sesija 02: Tipovi podataka u R i data.frame klasa
Fidbek se upućuje na goran.milovanovic@datakolektiv.com. Ova sveščica prati kurs Uvod u R programiranje za analizu podataka 2020/21.
U našoj Sesiji 02 nastavljamo da pravimo pregled nekih tipova podataka u R i bavimo se i dalje data.frame klasom. Pozbavićemo se dodatno i listama koje smo videli prošli put i opet ćemo malo da trčimo pred rudu da vidimo šta je to {dplyr} paket u {tidyverse} pristup R programiranju. Da ne zaboravim: ulazi na scenu predivna lapply() funkcija, a videćemo i kako se pišu naše funkcije u R!
0. Liste, data.frame i lapply()
Funkcija library() u R poziva određeni paket (biblioteku): najednostavnije rečeno, to je skup nekih dodatnih funkcija koje možemo da koristimo u našem radu. Paket {tidyverse} okuplja veliki broj drugih paketa u sebi od kojih su najpoznatiji {dplyr}, {tidyr} i {ggplot2}.
Vraćamo se iris skupu podataka:
library(tidyverse)
data(iris)
head(iris, 10)Hajde da iz iris isečemo jedan podskup koji će ponovo biti data.frame: samo posmatranja koja na varijabli Species imaju vrednost setosa. To radimo ovako:
setosa_frame <- iris[iris$Species == 'setosa', ]
dim(setosa_frame)## [1] 50 5head(setosa_frame)Jednostavna linearna regresija kojom hoćemo da proverimo da li na osnovu setosa_frame$Sepal.Length možemo da predvidimo setosa_frame$Petal.Length:
model <- lm(setosa_frame$Petal.Length ~ setosa_frame$Sepal.Length,
data = setosa_frame) Koje klase je varijbla model:
class(model)## [1] "lm"Klasa lm je skraćeno od “linear model”. Funkcija lm() može da izgradi najrazličitije linearne modele u R.
Koristimo {ggplot2} koji učimo iz knjige da napravimo skaterplot dve varijable koje smo koristili u modelu:
ggplot(data = setosa_frame,
aes(x = Sepal.Length,
y = Petal.Length)) +
geom_smooth(method = "lm", size = .25, color = "red") +
geom_point(size = 1.5, color = "red") +
geom_point(size = 1, color = "white") +
theme_bw()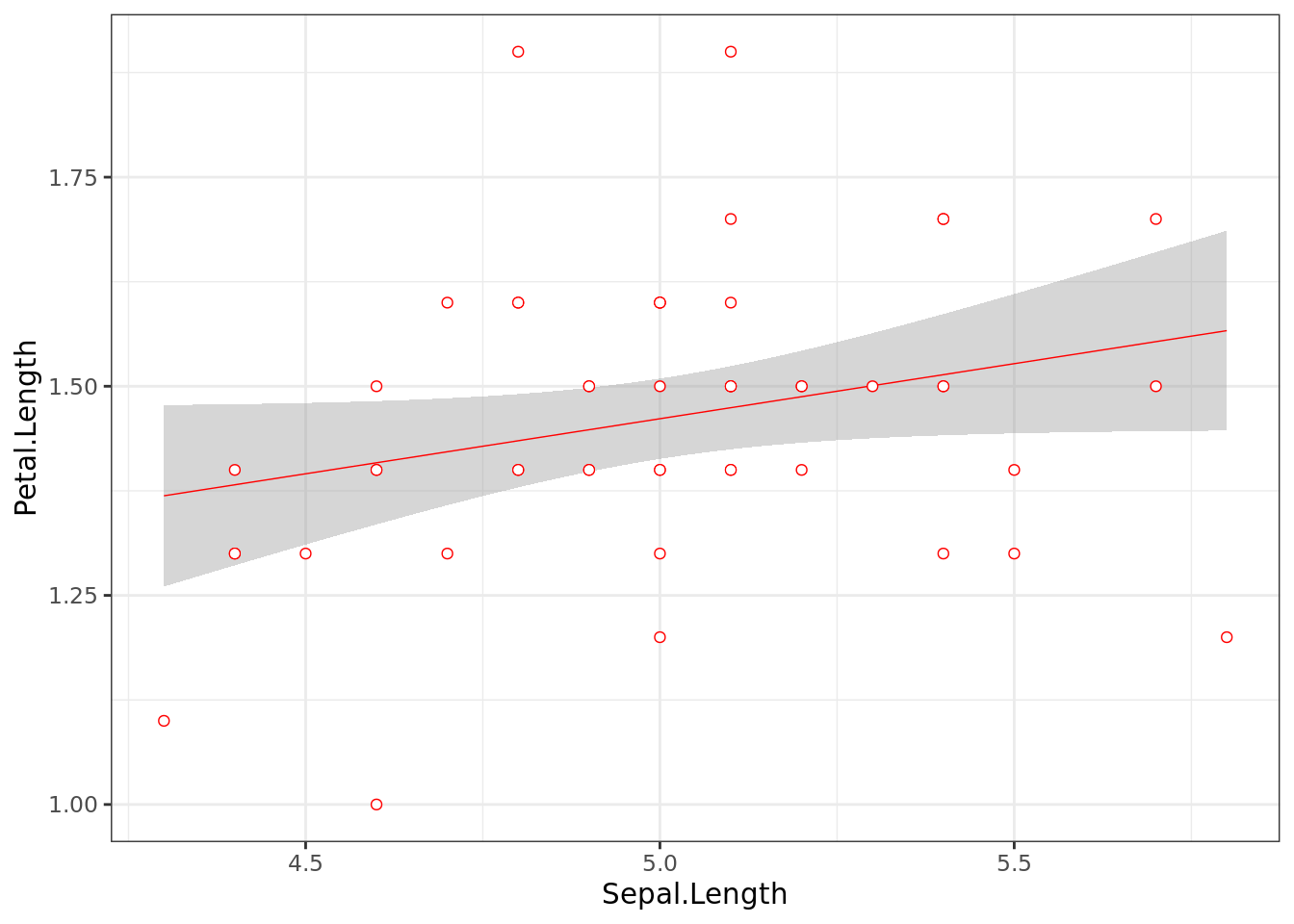
Šta je prednost R u odnosu na upotrebu klasičnog statističkog softvera? Automatizacija poslova, pored fleksibilnosti upravljanja podacima, je sigurno ključna stvar. Videli smo da u iris postoje tri podskupa po varijabli Species: setosa, virginica, i versicolor. Zamislite da hoću da izvedem tri linearne regresije, svaki put pokušavajući da predvidim varijablu Petal.Length na osnovu varijable Sepal.Length, ali tako prvi put radim samo na podskupu setosa, drugu regresiju samo na podskupu virginica, i treću na versicolor. Kako radim: formulišem jednu po jednu regresionu analizu?
Naravno, ne. To je R.
Sledeći kod: iris_species <- unique(as.character(iris$Species)) već razumemo iz prethodnih sesija. On nam daje sve jedinstvene elemente kolone iris$Species; pozive funkciji as.character() služi za konverziju tipa faktor u tip karakter (diskutujemo tokom sesije ovo).
Funkcija lapply() koju koristimo posle je jedna od najvažnijih funkcija u programskom jeziku R:
iris_species <- unique(as.character(iris$Species))
models <- lapply(iris_species, function(x) {
dataset <- filter(iris, Species == x)
model <- lm(dataset$Petal.Length ~ dataset$Sepal.Length,
data = dataset)
return(model)
})
names(models) <- iris_speciesŠta radi poziv funkciji lapply()? Ova funkcija primenjuje funkciju definisanu u svom pozivu na sve elemente nekog vektora ili liste. Taj vektor je u našem primeru iris_species koji smo dobili prethodnim izdvajanjem svih jedinstvenih vrednosti iz kolone iris$Species. Funkcija koja će biti primenjena na svaki element tog vektora u lapply() pozivu je definisana u samom lapply() pozivu i izgleda ovako:
function(x) {
dataset <- filter(iris, Species == x)
model <- lm(dataset$Petal.Length ~ dataset$Sepal.Length,
data = dataset)
return(model)
}Dakle, lapply() će na svaki element u iris_species primeniti ovu funkciju unutar koje se pozivom funkciji filter() iz {dplyr} paketa prvo uzimaju sve vrednosti Species == x, a zatim se pozivna funkcija linearnog modela lm() na dobijeni podskup skupa podataka iris. Kako x u pozivu funkcije kroz lapply() poziv sukcesivno uzima jednu po jednu vrednost iz iris_species, rezultat poziva će biti lista - lapply() uvek vraća listu rezultata! - koja sadrži kao svoje elemente jedan po jedan regresioni model ovako dobijen!
Na primer, drugi dobijeni regresioni model je:
summary(models$versicolor)##
## Call:
## lm(formula = dataset$Petal.Length ~ dataset$Sepal.Length, data = dataset)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.68611 -0.22827 -0.04123 0.19458 0.79607
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.18512 0.51421 0.360 0.72
## dataset$Sepal.Length 0.68647 0.08631 7.954 2.59e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3118 on 48 degrees of freedom
## Multiple R-squared: 0.5686, Adjusted R-squared: 0.5596
## F-statistic: 63.26 on 1 and 48 DF, p-value: 2.586e-10Da se malo vratimo klasičnom programiranju koje smo nekada učili u školi (makar BASIC): da smo nešto slično hteli da izvedemo FOR petljom, to bi u R izgledalo ovako:
for (i in 1:length(iris_species)) {
dataset <- filter(iris, Species == iris_species[i])
model <- lm(dataset$Petal.Length ~ dataset$Sepal.Length,
data = dataset)
print(summary(model))
}##
## Call:
## lm(formula = dataset$Petal.Length ~ dataset$Sepal.Length, data = dataset)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.40856 -0.08027 -0.00856 0.11708 0.46512
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.80305 0.34388 2.335 0.0238 *
## dataset$Sepal.Length 0.13163 0.06853 1.921 0.0607 .
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.1691 on 48 degrees of freedom
## Multiple R-squared: 0.07138, Adjusted R-squared: 0.05204
## F-statistic: 3.69 on 1 and 48 DF, p-value: 0.0607
##
##
## Call:
## lm(formula = dataset$Petal.Length ~ dataset$Sepal.Length, data = dataset)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.68611 -0.22827 -0.04123 0.19458 0.79607
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.18512 0.51421 0.360 0.72
## dataset$Sepal.Length 0.68647 0.08631 7.954 2.59e-10 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.3118 on 48 degrees of freedom
## Multiple R-squared: 0.5686, Adjusted R-squared: 0.5596
## F-statistic: 63.26 on 1 and 48 DF, p-value: 2.586e-10
##
##
## Call:
## lm(formula = dataset$Petal.Length ~ dataset$Sepal.Length, data = dataset)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.68603 -0.21104 0.06399 0.18901 0.66402
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.61047 0.41711 1.464 0.15
## dataset$Sepal.Length 0.75008 0.06303 11.901 6.3e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2805 on 48 degrees of freedom
## Multiple R-squared: 0.7469, Adjusted R-squared: 0.7416
## F-statistic: 141.6 on 1 and 48 DF, p-value: 6.298e-16Ali u funkcionalnom programskom jeziku kao što je R nema potrebe ovo da radimo i u principu izbegavamo iteracije (petlje) gde god možemo!
Čitanje za narednu sesiju
- Poglavlja 11 - 16 iz R for Data Science, Hadley Wickham & Garrett Grolemund.
R Markdown
R Markdown je ono što koristimo da bismo razvili ove sveščice. Evo knjige iz koje se može naučiti rad u toj jednostavnoj ekstenziji R: R Markdown: The Definitive Guide, Yihui Xie, J. J. Allaire, Garrett Grolemunds..
![]()
Goran S. Milovanović, Data Scientist & Vlasnik, DataKolektiv.
Kontakt: goran.milovanovic@datakolektiv.com. Ovo je besplatan i slobodan softver: GPL v2.0.
